

A Merkle Tree is a method of structuring data that allows a large body of information to be verified for accuracy extremely quickly and efficiently. Every Merkle tree results in a single string of data, known as the Merkle root. With the Merkle root, plus a few other pieces of data, any computer can efficiently validate all of the other entries in the Merkle tree. In blockchain technology, these entries are transaction identification numbers.
If you’re involved in the world of blockchain, you may have come across the phrase "merkle tree" before. While Merkle trees are not a widely-understood concept, they’re also not terribly complicated. This post will explain Merkle trees in plain English and help you understand how they make blockchain technology possible.
All About Merkle Trees
The story of Merkle Trees begins way back in 1979 with a guy named Ralph Merkle. While in grad school at Stanford University, Merkle wrote an academic paper called “A Certified Digital Signature.” In this essay, Merkle described a method for creating digital signatures and established a new, extremely efficient method of creating cryptographic proofs. In other words, he designed a process for verifying data that would allow computers to do their work much, much faster than ever before.
Merkle called his idea "Tree Signatures" or "Tree Authentication. Nowadays, this idea is better known as a Merkle Tree, named after the inventor.

It's no exaggeration to say that Merkle Trees revolutionized the world of cryptography and, by extension, the way that encrypted computer protocols function. In fact, Merkle Trees are mentioned repeatedly in Satoshi Nakamoto’s 2008 essay that introduced Bitcoin to the world. They’re used extensively in the Bitcoin protocol.
So, what exactly is a Merkle Tree? Let's find out.
First, it’s important to understand the concept of a cryptographic hash function. Stated simply, hash functions are irreversible mathematical functions that take an input of any length-- from one character to the text of an entire set of encyclopedias-- and produce a random output of a fixed length. Because the output appears random and is of fixed length, an attacker has no clues about what input created a specific output. Hash functions are also deterministic so the same input will always produce the same output. Lastly, hash functions are irreversible, so there is absolutely no way to ascertain an input from knowledge of the output alone.
Learn more about hash functions in this guide.
All of these properties enable hash functions to create electronic fingerprints of a particular input. Using hash functions, blockchain networks create a cryptographic hash-- an electronic fingerprint-- of each transaction. The cryptographic hash of a transaction is simply called the transaction ID. For almost every blockchain protocol, each transaction ID is a 64-character (256-bit) alphanumeric string of data.
When you consider that blockchains are typically made up of hundreds of thousands of blocks, with each block containing as many as several thousand transactions, you can imagine how quickly verification of transactions might become computationally difficult. As such, it’s optimal to use as little data as possible when processing and verifying transactions. This minimizes CPU processing times while also ensuring the highest level of security.
Well, that’s exactly what Merkle Trees do. To put it very simply, Merkle Trees take a huge number of transaction IDs, structure them in a specific way, and use cryptographic hash functions to derive a single, 64-character alphanumeric string that acts as an electronic fingerprint for the entire body of data.
This string of data, called the Merkle Root, is extremely important because it allows any computer to quickly verify that a specific transaction took place on a particular block as efficiently as possible.
What’s A Merkle Root?
The single 256-bit string that a Merkle Tree produces is called the Merkle Root. Each block in a blockchain has exactly one. And, as we just mentioned, the Merkle Root is a crucial piece of data because it allows computers to verify information with incredible speed and efficiency.
Let’s dive a little deeper. How is a Merkle Root produced? The first step is to organize all of the data inputs which, in this case, are transaction IDs. Merkle Trees, by design, always group all of the inputs into pairs. If there is an odd number of inputs, the last input is copied and then paired with itself. This holds true for all the transaction IDs written onto a block of a blockchain.
For instance, let’s suppose that a single block contains a total of 512 transactions. The Merkle Tree would begin by grouping those 512 transactions IDs into 256 pairs. Then, those 256 pairs of transaction IDs would go through a mathematical process-- the hashing function or hashing algorithm, as it's sometimes called-- and we would have 256 new, 64-character cryptographic hashes.
The same exact process occurs again. Those 256 new hashes would be paired up and turned into 128 hashes. The process is repeated, cutting the number of hashes in half each time, until only a single hash remains. That single hash is our Merkle Root.
A Simple Example Of A Merkle Tree
To make this concept clear, let’s look at a very simple example of a Merkle Tree. Imagine that there were 8 transactions performed on one particular block. In reality, transaction IDs are 64 characters long, but for the sake of simplicity, let’s pretend that they’re only 8 characters long. To make things even easier, let’s use only numbers (and ignore letters altogether).
So, in this example, our eight transactions IDs will be:
- 11111111
- 22222222
- 33333333
- 44444444
- 55555555
- 66666666
- 77777777
- 88888888
Now let’s suppose that the method for hashing transaction IDs together is to take the first, third, fifth, and seventh digits from each of the two IDs being combined, and then simply push those numbers together to form a new, 8-digit code.
Of course, in reality, the mathematics behind hashing algorithms is far more complicated than this. But for this simple demonstration, this elementary system will suffice.
This is what our Merkle Tree would look like:
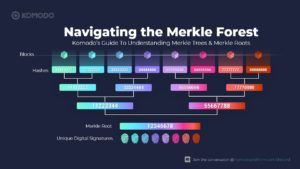
Notice that the number of codes is cut in half each step down the Merkle Tree. We start with 8 transaction IDs and, after just 3 steps, end up with a single code—the Merkle Root. In this example, our Merkle Root is the code in the bottom box: 12345678.
The primary benefit of Merkle Trees is that they allow extremely quick verification of data. If we want to validate a single transaction ID, we wouldn’t need to double-check every single transaction on the block. Rather, we would only need to verify that particular “branch” of our Merkle Tree.
Efficiency And Speed: The Benefits Of Merkle Trees
Let’s suppose that we want to validate a transaction ID in our current example. Bob says that he paid Alice a certain sum of Bitcoin and tells us that the transaction ID is 88888888. He also sends us 3 hashes: 77777777, 55556666, and 11223344. That’s all the info that needs to be sent or received to verify Bob’s payment to Alice.
These three hashes, along with the transaction ID in question and this particular block’s Merkle Root, are the only data needed to verify Bob’s payment to Alice. This is far less data than what would be required to verify the entire Merkle Tree. As a result, the verification process is much faster and far more efficient for everyone.
Here’s how it works. We already have the block’s Merkle Root, so Bob doesn’t need to send us that. He sends us his transaction ID and the 3 additional hashes we listed above. He also sends a tiny bit of information about the order and placement in which to use the hashes. Now, all we have to do is run the hashing algorithm on the set of data Bob provided.
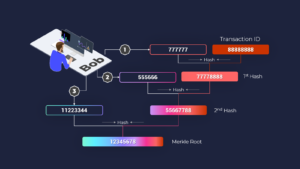
We start by hashing the first code 77777777 with the transaction ID 88888888, which gives us the result 77778888. Bob didn’t send us this code but he didn’t need to because we’re using the same hashing algorithm as him. Therefore, we receive the exact same results.
We then take the second code Bob sent us, 55556666, and hash it with the new code 77778888 we just derived. This, of course, produces the number 55667788.
Finally, we hash the third code Bob gave us, 11223344, with the other new code we received, 55667788, and we end up with the correct Merkle Root: 12345678.
Notice that we only need 3 codes from Bob and only had to run the hashing algorithm three times to see that Bob’s transaction is valid. That means our computer has done less than half the work that would’ve been required to verify the entire Merkle Tree. The original Merkle Tree diagram has 15 numbers and the hashing algorithm needs to be run 7 times. But more than half of that tree isn’t necessary to verify Bob’s transaction!
Validation Procedures Made Simple With Merkle Tree
This procedure is sufficient to verify that Bob did, in fact, pay Alice that certain sum of Bitcoin because we derived numbers that, when hashed together with the other codes Bob sent us, produced the same Merkle Root that we already knew to be true for this particular block.
Bob can’t fake a transaction because that would require finding a fake transaction ID and an additional set of fake codes that, when put through the hashing function, would produce the true Merkle Root. The chances of this happening are so astronomically small that we can confidently say it’s impossible.
In this simple example, the savings of computing power might not seem substantial. However, when you consider that blocks in a blockchain might contain several thousand transactions, it’s easy to see how Merkle Trees increase efficiency so dramatically.
In short, that’s the main benefit of a Merkle Tree. It allows computers to verify information extremely efficiently and with far less data than what would be required without the Merkle Tree.
Merkle Trees are also the foundational concept in Komodo Platform’s solution to the blockchain scalability problem. Komodo’s scaling solution allows complete blockchain interoperability and will allow Komodo to process transactions faster than any other payment processing service on the planet. Currently, Komodo's new scaling tech is processing over 20,000 transactions per second in a testing environment.
📧Komodo Newsletter
If you'd like to learn more about blockchain technology and keep up with Komodo's progress, subscribe to our newsletter. Begin your blockchain journey with Komodo today.